刘明辉,唐望径,许 斌,仝美涵,王黎明,钟 琦,徐剑军
1.清华大学计算机科学与技术系,北京 100084
2.中国科普研究所,北京 100081
3.北京彩智科技有限公司,北京 100081
命名实体识别(named entity recognition,NER)是信息抽取(information extraction,IE)的子任务之一,是自然语言处理(natural language processing,NLP)的核心任务之一,广泛应用于信息检索、自动文本摘要、问答任务、机器翻译以及知识图谱构建等领域。NER 任务旨在从文本中识别出包含特定意义的对象,包括人名、地名、组织名称、专有名词等。NER模型的实现方法可分为基于规则或词典的方法、无监督方法以及有监督方法[1]。
基于规则或词典的方法是NER 中最早使用的方法。基于规则的方法大多由语言学领域专家通过手工构造实体抽取规则模板的方式,以模式和字符串匹配作为主要手段[2]。这类系统大多依赖于知识库和词典的建立,一般而言,当规则设计合理时,基于规则或词典的命名实体方法能够得到较高的精确率,但在召回率上表现较差。同时,这些语言规则往往依赖于具体的语言、实体抽取所处领域以及抽取文本的风格,极易产生错误,可移植性较差。
基于监督学习的方法包括浅层学习和深度学习。早期浅层学习模型通常采用人工特征工程的方法获取适当的文本特征以表征样本,之后将特征输入统计学习模型,如支持向量机(support vector machine,SVM)[3-4]、隐马尔可夫模型(hidden Markov model,HMM)[5-6]、最大熵模型(max entropy model,MEM)和条件随机场(conditional random field,CRF)[7-8]等。浅层学习模型通常需要设计特征提取方法,需要大量的人力和较高的时间成本。
随着深度学习方法在NLP 领域的广泛应用,深度神经网络也成功应用到NER 任务中,并且取得了优异成果。基于深度学习的NER 方法通常将NER 任务视作为序列标注任务。当前主流的基于深度学习的序列标注模型通常由嵌入层、编码层和解码层3 个模块构成[9],通过嵌入层将文本中所有字生成为相应的字向量,通过编码层对字的上下文进行编码以获取语义信息,之后通过解码层生成对应的标签。深度学习模型在NER 任务中取得了巨大的成功,而循环神经网络(recurrent neural network,RNN)因其能够捕获长距离依赖的特性成为序列标注任务中常用的编码器。文献[10]利用卷积神经网络提取单词的字符级特征表示向量,将字符表示向量与单词的嵌入连接并以RNN 作为编码器进行编码,最终实现对输入文本中蕴含实体的自动识别。文献[8]提出了基于Bi-LSTM 和CRF 的NER 模型,该模型能够利用Bi-LSTM 模型的双向编码能力对上下文信息进行编码,并通过CRF 模型学习标签之间的序列顺序,成为当下最为主流的NER 模型。
在中文NER 任务中,以词语为基础单元的模型往往因为分词错误的累积传播而影响实体识别的效果,所以目前主流的方法是上文提到的以字符为基础的编码器-解码器模型。然而,与英文不同的是,中文语境中的词语包含大量语义信息,但是在字符级别的NER 模型中,词语的信息不能被完全利用。因此,研究人员开始尝试向模型中添加词汇信息以提高识别效果。近年来,基于词汇增强的中文NER 方法主要分为两类:动态框架法和自适应嵌入法。
动态框架法通常需要设计相应结构以融入词汇信息。文献[11]提出的Lattice-LSTM 模型通过Bi-LSTM 模型编码层的修改在字向量中编码了词语的信息,帮助模型更好地区分实体边界,有效地提高模型的识别性能。但是该模型计算性能低下,不能实现批量数据并行化训练;
且通用性差,只适配于LSTM 而不能向其他模型迁移。文献[12]针对Lattice-LSTM运行效率低和词汇信息冲突的问题提出了LR-CNN 模型,使用卷积神经网络对字符进行编码,采取注意力机制融入词汇信息,并且利用全局信息缓解了词汇信息冲突问题。LR-CNN相比于Lattice -LSTM 的运行速度提升了3.21 倍,但该模型计算依然复杂,不具备可迁移性。文献[13]将协作的图网络引入中文NER,并在图网络层使用3 种不同的构图方式获取不同的信息,取得了良好的效果。文献[14]针对Lattice-LSTM 不能利用全局信息的问题,考虑基于词汇的信息来构建图网络,增加全局节点以融入全局信息,将中文NER 问题建模成图节点分类问题,并通过实验证明了图方法在中文NER 任务中的有效性。文献[15]提出了FLAT(Flat-Lattice Transformer)模型,该模型基于Transformer[16]将Lattice-LSTM 中的格子结构转化为平面结构,并引入相对位置编码对Lattice-LSTM 计算效率低下、引入词汇信息不全这两点不足之处加以改进。然而,FLAT 等模型在引入词语的信息时没有考虑词集之间的重要度差异,于是文献[17]将词集级注意力机制引入中文NER 方法,并根据字在词中的位置划分词集,建立词集级别的注意力机制,使注意力集中在重要的词集上,以此提高NER的效果。
自适应嵌入法仅在嵌入层对词汇信息进行自适应,在嵌入层后面可以接入各种编码器与解码器。这种范式与模型无关,故具备可迁移性。文献[18]为了解决Lattice-LSTM 不能批量并行化的问题,提出了一种将每个字符为结尾的词汇信息进行固定编码表示的新策略,从而实现了并行化训练,充分发挥了GPU 的性能。文献[19]与其他工作不同,在引入词汇时不是使用Lattice-LSTM 提供的预设词表,而是采用了一种基于图神经网络结合多种词典的NER方法,让模型自动地学习词典的特征,解决了词典匹配冲突的问题。文献[20]发明了一种在嵌入层简单使用词汇的方法,尝试了Softword、ExtendSoftword、Soft-lexicon 等3 种不同的融合词汇的方法,最终使用Soft-lexicon 方法解决了Lattice-LSTM 通用性差、信息损失多的问题。
针对字符级别NER 模型不能利用词语信息的问题,本文首先使用分词工具对训练集进行全模式分词,选出所有可能成词的词语构建词表;
然后利用通用知识图谱检索词表中实体的类别信息,并按照字符在词中的位置划分与字符相关的词集,再根据词集中实体对应的类别信息生成实体类别信息集合;
接着使用词嵌入的方法将类别信息的集合转换成向量与字符向量拼接;
最后用Bi-LSTM 提取时间序列信息,以CRF 模型作为解码器完成NER 任务。本文的创新点如下:1)提出了基于通用知识图谱中实体类别信息知识增强的中文NER 方法;
2)在中文NER 数据集MSRA 上进行的实验验证了模型的有效性,相较于Bi-LSTM 与Bi-LSTM+CRF 模型,在评价指标F1上分别提升了11.00%与3.09%。
NER 是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。本文将NER 任务刻画为序列标注任务并给出如下定义:向模型输入一个自然语言序列S={c1,c2,···,cn},模型的输出为Y={y1,y2,···,yn},yi ∈{B,I,O},其中,B和I标签分别表示该字符在一个命名实体的起始和中间位置,O表示该字符不属于命名实体。
本文提出的NER 算法的主要贡献在模型的嵌入层。首先将输入序列的每个字符映射到高维空间向量;
然后根据字符在词中的位置划分与字符相关的词集,则与词集对应的类别信息构成类别信息集合;
接着将类别信息集合映射至向量并拼接到字符的表示中;
最后将这些增强字符表示放入序列建模层和CRF 层,得到最终的预测结果。模型整体架构如图1所示。
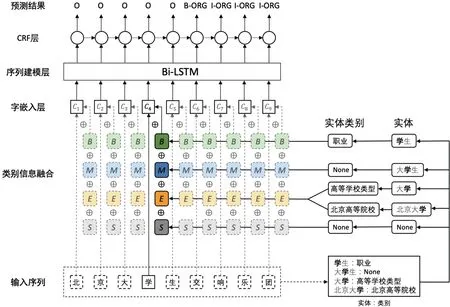
图1 模型架构Figure 1 Model architecture
本文提出的基于实体类别信息增强的命名实体模型框架共包括3 个模块:字嵌入层、编码层、解码层。1)在字嵌入层,采用字嵌入模块将输入序列中的字符映射至高阶向量空间中的字向量,并与实体类别信息转化的向量融合。2)在编码层,使用Bi-LSTM 进行特征提取,既能利用RNN 提取序列信息的能力对字的上下文进行编码以获取双向语义信息,又能缓解因长序列带来的梯度爆炸和梯度消失问题。3)在解码层,利用CRF 进行解码,学习标签之间的序列顺序,最终得到序列对应标签。
NLP 任务中的嵌入层通常可以使用Pytorch 自带的nn.embedding() 方法实现。在实现字嵌入的过程中,嵌入层的权重用于随机初始化字符的向量,该权重随训练过程并根据训练目标不断优化。本文模型中字嵌入的实现方法与上述一致,首先将训练集中的句子分割,生成字符的集合,并使每一个字符与唯一的编号相对应;
然后将句子中的字符转换为编号输入嵌入层,再由嵌入层将独热序列映射成高维的向量表示。
本文提出的模型在字嵌入层融合了实体的类别信息,融合过程分为5 个步骤。
步骤1构建候选词集。使用jieba 分词工具构建候选词集,jieba 的全模式分词能够将句子中所有可以成词的词语扫描出来,虽然速度非常快,但是不能解决歧义问题。下面通过实例加以说明。
句子:英皇家音乐学院交响乐团来华交流演出。
全模式分词:英皇皇家音乐音乐学音乐学院学院交响交响乐交响乐团乐团来华交流演出。
对训练集、验证集、测试集中的句子使用jieba 的全模式分词,获得所有可能成词的词语,去除重复的词语,则可以得到候选词集。
步骤2获得候选词中实体的类别信息。维基百科是一个网络百科全书项目,各个版本的条目之和已经超过5 300 万条,是全球网络上最大且最受大众欢迎的百科网站。根据维基百科中结构化知识构建的知识图谱Wikidata 是目前世界上最大的通用知识图谱之一。维基百科蕴含丰富的结构化知识,其中条目的类别信息对于指导实体知识增强以及提高NER 模型的性能具有现实意义。
构建候选词集后,通过遍历候选词集中的词语来检查这些词语是否为维基百科中的条目。若是,则保存该词语的类别信息;
若不是,则为该词记录一个空白符号None,代表该词没有类别信息。
步骤3划分与输入序列中字符相关的词语。文献[16]提出了一种名为Soft-lexicon 的方法,该方法简单而有效,能从词集中划分出与某个字符相关的词语。具体来说,可以把与一个字符相关的词语划分为4 个集合,分别为Begin、Middle、End、Single 集合,在下文中用相应的首字母B、M、E、S表示。对于一个输入序列S={c1,c2,···,cn}中的字符ci,定义wi,j为输入序列中位置i到j的词语,则B、M、E、S集合构造为
式中:L为步骤1 构建的候选词集。若在B、M、E、S某一个集合中没有词语,则增加一个None 字符。
步骤4将与字符相关的词集转化为与字符相关的类别信息集合。经过步骤2 已经获得候选词集中所有实体的类别信息,因此只需将字符的B、M、E、S集合中的词语换成该词语的类别,即可获得字符相关词语的类别信息集合。
步骤5将类别信息集合映射为高维向量,与字符嵌入融合。创建一个新的embedding层,将字符的类别信息集合转换为向量。若一个集合中有多个词语,则对词向量求平均得到集合的向量,其计算公式为获得实体类别信息集合的向量后,将其与字符嵌入拼接传入编码层。
RNN 以序列数据为输入,能够在时间维度提取序列中蕴含的信息。长短期记忆网络(long short-term memory,LSTM)是RNN 的一种,该模型解决了传统RNN 模型长期依赖的问题。LSTM 模型结构包括遗忘门、输入门、输出门。在t时刻,首先通过遗忘门选择性地遗忘上一时刻中的信息,其计算公式为
式中:xt为t时刻的输入;
ht−1为上一时刻的输出;
ft ∈[0,1],表示信息的保留程度。之后通过输入门决定当前时刻需要记录的信息,其计算公式如式(4)~(6) 所示:
式中:Ct表示当前时刻的状态信息,将会传递至下一时刻。之后通过输出门控制当前时刻状态信息的输出,其计算公式如式(7) 和(8) 所示:
式中:ht将作为时刻t的最终输出传递至下一时刻,并不断重复。
LSTM 模型虽能解决长期依赖问题,但不能捕获序列的双向信息。为优化LSTM 模型,出现了Bi-LSTM 模型。该模型由前向LSTM 和反向LSTM 模型构成,其模型如图2所示。

图2 Bi-LSTM 模型结构Figure 2 Structure of Bi-LSTM model
相比于其他以Softmax 作为解码器的任务,NER 任务中相邻标签通常具备更多的相关性[10]。假定输入序列S={x1,x2,···,xn},序列对应标签为Y={y1,y2,···,yn},其得分为
式中:A表示转移得分矩阵,矩阵元素Ai,j表示标签i向j转移的转移得分。最终解码时通过维特比(Viterbi)算法得到得分最大的预测标签序列为
实验数据来自微软亚洲研究院MSRA 数据集,共包含48 442 个句子和3 类通用领域实体,这3 类通用领域实体分别为人物、地点、组织。数据集详情如表1所示。

表1 数据集详情Table 1 Dataset statics个
实验模型采用Pytorch 搭建,基于Dropout 算法防止模型过拟合。实验中出现的所有模型均为基于字级别的实体抽取模型,具体参数如表2所示。

表2 模型参数设置Table 2 Model parameter setting
实验运行服务器配置为Intel®CoreTMi9-10900K CPU,显卡为RTX 3090。
本文使用精确率、召回率和F1分数作为评价指标,分别用P、R和F1表示,并且遵循精确匹配[21]的标准计算分数。
为验证本文提出的NER 模型在中文数据集上的性能,引入了最经典的Bi-LSTM 模型、Bi-LSTM+CRF 模型作为对比的基线模型,并在MSRA 数据集上进行对比实验。本文提出的方法用知识增强(knowledge enhanced,KE)模块表示,实验结果如表3所示。
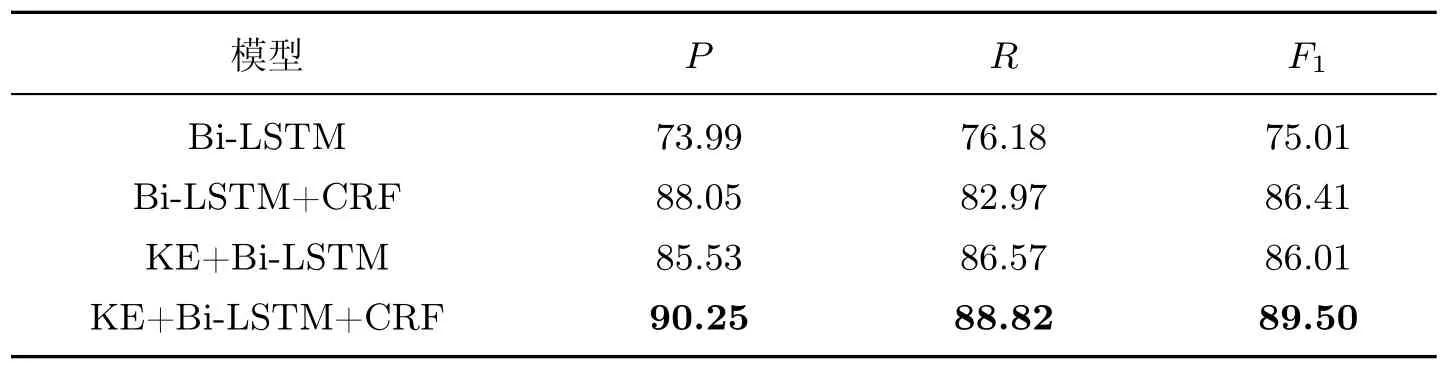
表3 MSRA 数据集中对比实验结果Table 3 Comparison of experimental results in MSRA dataset%
从表3中可以看出:本文提出的基于知识图谱实体类别信息增强的NER 模型在MSRA数据集中取得了最好的效果,其精确率、召回率和F1均为最佳,分别达到了90.25%、88.82%和89.50%,相比于基线模型中效果最好的Bi-LSTM+CRF 模型,在评价指标F1上提高了3.09%。
对比数据结果可以发现,使用CRF 作为解码器的模型在各项指标中均远优于不使用CRF作为解码器的模型。Bi-LSTM+CRF 模型较不使用CRF 的Bi-LSTM 模型在评价指标F1上提高了11.40%;
当使用本文提出的方法时,使用CRF 作为解码层的KE+Bi-LSTM+CRF 模型比KE+Bi-LSTM 模型在评价指标F1上提高了3.49%。
对比上述实验可知,以实体的类别信息对NER 模型进行知识增强能够提升模型性能,分别在P、R、F1指标上提升了2.20%、5.85%、3.09%。
考虑到现有字级别的中文NER 模型没有充分利用词汇信息的问题,本文提出了基于知识图谱实体类别信息增强的NER 方法。先对训练集、验证集、测试集中的句子进行全模式分词获得候选词集,再从维基百科中遍历候选词集,保存实体的类别信息;
接着使用Soft-lexicon方法得到与字符相关的词集,更换词语为实体的类别信息后,将实体类别信息集合转化的向量与输入序列的字嵌入拼接,通过Bi-LSTM 对输入序列信息进行特征提取;
最后采用CRF模型进行解码得到NER 标签。实验结果表明:本文提出的KE+Bi-LSTM+CRF 模型能在中文公开数据集中有效提升实体识别性能,相较于Bi-LSTM+CRF 模型,在评价指标F1上提高了3.09%。
文献[22]将NER 任务划分为通用型NER 和特定领域NER。本文的实验结果证明了基于通用知识图谱进行数据增强的方法在中文数据集中是有效的,相比于通用领域图谱,特定领域知识图谱中的内容更加专业,实体类别所蕴含的信息更多,对模型的增强效果可能更强,故后续可尝试将工作转移至特定领域NER 任务中进行研究。
猜你喜欢字符类别实体字符代表几小学生学习指导(低年级)(2019年12期)2019-12-04前海自贸区:金融服务实体中国外汇(2019年18期)2019-11-25一种USB接口字符液晶控制器设计电子制作(2019年19期)2019-11-23HBM电子称与西门子S7-200系列PLC自由口通讯数字通信世界(2019年3期)2019-04-19消失的殖民村庄和神秘字符少儿美术(快乐历史地理)(2018年7期)2018-11-16壮字喃字同形字的三种类别及简要分析民族古籍研究(2018年1期)2018-05-21实体的可感部分与实体——兼论亚里士多德分析实体的两种模式哲学评论(2017年1期)2017-07-31两会进行时:紧扣实体经济“钉钉子”领导决策信息(2017年9期)2017-05-04振兴实体经济地方如何“钉钉子”领导决策信息(2017年9期)2017-05-04服务类别新校长(2016年8期)2016-01-10




