余晨,张泽,吉晶
(中移信息技术有限公司,广东深圳,5 180481)
目前在老年人市场研究方面,主要总结有两部分,一方面是对银发市场的市场前景、经济潜力、现状问题等方面的专业评析研究,另一方面是对于老年特定人群或特定行为进行了一些数据技术识别。魏姗姗[1]等基于手机信令数据,建立了贝叶斯分类器进行老年人群识别。冯先成[2]等采用前馈神经网络算法对空巢老人手机用户进行识别分析。李力行[3]等基于通话费用、上网费用及时长及短信费用等电信数据进行空巢老人评判指标设计。吕子阳[4]等通过建立广义回归神经网络(GRNN)、概率神经网络(PNN)和误差逆传播神经网络(ВPNN)三种神经网络模型建立易跌倒老人识别模型。潘宇欣[5]等提出基于随机森林和行为相似性的两层行为识别算法用以识别老人居家行为。赵春阳[6]构建一种卷积神经网络和循环神经网络相结合的混合模型对老年居家行为进行识别,以提高老年居家生活质量。刘琳[7]利用不同的神经网络模型对老人日常活动所产生的传感器数据进行活动识别。周洁[8]使用Logistic 回归、随机森林、XGВoost 算法建立脑卒中风险预测模型,实现老年人高血压并发症高危个体识别。李彩福[9]等运用反向传播神经网络机器学习算法构建衰弱前期预测模型,为早期识别社区老年衰弱前期高危人群提供参考。张庆莉[10]结合模式识别技术、语音信号处理技术、语音情感识别技术,使用高斯混合模型进行了老年人语音情感识别研究。
关于老年人群体的识别方面较多使用的有监督算法,根据已有的是否老年人标签进行分析挖掘,例如常用的贝叶斯分类、随机森林、反向传播神经网络等,但结合现实的业务需求,较多业务场景是需要挖掘识别潜在用户中的老年人群体,但是受限于已有数据的采集信息范围,面向大部分潜在客户都是无法有明确标签标记是否为老年人,因此有监督算法在现实场景中的作用发挥有限。针对上述问题,本文提出一种基于用户通信数据的潜在老年用户识别模型,通过PU learning 算法在半监督场景下对未有明确标记的数据样本进行老年人群体判别,同时使用AutoEncoder 算法得到误差阈值同步进行判别,最后为提升识别的准确性,对两种算法均识别出的综合老年人群根据结果预测概率和预测阈值进行1-5 分赋值,计算综合得分,取综合得分大于等于8 分的人群识别为老年用户。
2.1.1 PU learning 算法
通常有监督算法是一种针对有明确正负标签的两类样本的二值分类器,但大多数情况下现有训练样本是已标记的正样本和未标记样本,其中未标记样本包括正样本和负样本[11],PU learning 算法则是针对这样场景的一种学习算法。首先对样本做软标签,正样本记为1,未标记的样本记为-1,准备标签0 作为确认的负样本。其次构建分类器,选用随机森林算法,保留每个样本的预测概率,并取正样本预测概率的最大值和最小值作为真实区间。第三更新软标签,对于未标记样本中,预测概率大于真实区间最大值的记为1,预测概率小于真实区间最小值的记为0。最后基于每次迭代构建的分类器,每次重新定义真实区间,将未标记标签区分为正样本和确定的负样本。不断更新直到循环结束或不产生新的0、1 标签,从而得到最终的判别结果。
2.1.2 AutoEncoder 算法
自编码器是一类在半监督学习和非监督学习中使用的人工神经网络,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习[12-13]。构建一个神经网络模型,将已有正样本标签数据作为输入进行模型训练,模型通过加解密尽量还原正样本标签数据的特征,得到正样本标签数据的还原误差范围。把样本标签数据放到模型中,通过还原误差阈值的区分观察两者区分度判断识别效果。根据模型测试效果选取合适的还原误差阈值,对预测样本进行输出结果分析,根据是否大于设定的阈值来进行人群识别。
通常情况下,潜在用户群体的识别往往具备较为明显的群体特征以及能够获得明确的样本标签,这些因素帮助机器学习算法通过较小的学习成本达到相对优秀的识别效果。但在一些特殊场景下,原始数据中大量行为模糊的正样本混杂在负样本中,而不可靠的负样本将极大程度上影响模型的准确性。因此在此场景下需要采用一些半监督算法对待识别用户群体进行分类,减少混杂样本的干扰、提升模型的准确性。潜在老年用户识别问题即为此类场景,设计基于用户通信数据的潜在老年用户识别模型如图1 所示。

图1 基于用户通信数据的潜在老年用户识别模型
基于用户通信数据的潜在老年用户识别模型的具体步骤如下所示:
步骤1:对原始数据集进行数据预处理和特征提取。部分算法对异常值较为敏感,可根据字段定义及字段之间逻辑关系去除异常值。
步骤2:对新构建的数据集分为训练集D 和测试集T。其中训练集D 包含两类样本:正样本D1和待定样本Dn,待定样本即为不可靠的负样本。
步骤3:选择PU learning 算法、AutoEncoder 算法作为学习器展开训练。
步骤3-1:在PU learning 算法中,采取两步法进行模型构建。在第一步中选择一种二分类学习器对训练集D 进行训练,得到对应预测概率P。根据正样本D1对应的最大概率和最小概率得到正样本真实区间(P1,P2)。以该区间作为划分依据,训练集D 中概率超过P2的待定样本与正样本D1合并确定为新的正样本,低于P1的待定样本确定为新的负样本,从而产生新的三分类训练集Da,包含正样本Da1,负样本Da2和处于(P1,P2)区间的待定样本Dan。第二步选择一种三分类学习器,对训练集Da进行训练。根据正样本Da1对应的最大概率和最小概率得到新的真实区间(Pa1,Pa2),按第一步相同的划分原则更新训练集Da,进行反复训练迭代,每次重新定义真实区间,将待定样本Dan区分为正样本和确定的负样本直到循环结束或不产生新的0、1 标签。
步骤3-2:在AutoEncoder 算法中,即构建一个神经网络模型,将正样本D1作为输入进行模型训练,模型通过加解密尽量还原D1的特征,根据还原结果确定D1的平均绝对误差mae 范围。
步骤4:将测试集T 代入完成训练的PU learning 和AutoEncoder 模型中进行模型评价优化,分别产生标签为1 的预测结果T1和T2。
步骤5:根据预测结果T1的概率范围均分为5 个区间并由低到高赋予1-5 分,根据预测结果T2的mae 范围均分为5 个区间并由低到高赋予1-5 分,两项预测结果数据集合并,两模型共同命中的用户根据其概率值和mae 值所落区间相加计分,使识别人群总得分区间保持在[0,10]之间,根据实际业务要求以阈值分数以上的预测数据作为最终输出结果。
在实际生活中,经常存在子女为父母代办手机号码或父母使用子女手机副卡的情况,此类老年人用户无法通过实名制身份证筛选获得,导致各类推荐信息无法触达。因此模型目标为基于用户通信数据识别隐藏在年轻人手机号码下的老年人群体。
本文抽取某省用户的通讯行为数据作为原始数据集。对原始数据集进行数据清洗,剔除异常值、极端值,补充缺失值,并针对不同特征之间量纲差别较大的问题,采用极大极小归一化的方式对数据进行标准化。
通过对原始数据集的特征进行重建和相关性筛选,选择了5 个维度中分别选择44 个和19 个比较有代表性的特征作为PU learning 和AutoEncoder 算法的输入特征进行模型建设。方案特征举例说明如表1 所示。

表1 方案特征举例说明
抽取原始数据集中10 万真实老年人群作为正样本,10万待识别人群作为待定样本,组成训练集,随机抽取近20万人群作为测试集,使测试集符合真实年龄分布。为了获得更好的评估模型效果,本文在测试集设置时对待测样本进行了处理,将待测样本中特征较为明显的部分年轻人群体作为真实负样本进行标注,观察算法的识别效果。训练集、测试集样本分布如表2。

表2 样本分布表
3.3.1 模型评价指标
受不可靠负样本的影响,测试集中其他待定样本的分类结果不能说明模型实际效果。因此在此类模型的评价指标中,主要关注正样本和真实负样本之间的查准率和查全率。此外,其他待定样本中预测为正的样本数占其他待定样本总数的比例(r)将作为一项辅助指标进行观测。
根据样本真实类别与学习器预测类别的组合,在常规的真正例(TP)、假正例(FP)、真反例(FN)、假反例(TN)四种情形之外,对其他待测样本中的预测结果为正的样本记为XP,预测结果为负的样本记为XN,如表3 所示。精准率P、召回率R、待定样本识别比例r 分别定义为公式(1)~(3)。

表3 真实类别与预测类别说明
3.3.2 PU learning 模型分类能力分析
PU learning 两步法计算时,使用随机森林作为二分类学习器对训练样本进行训练预测,得到正样本对应的概率区间[0.45,0.7]。以该区间作为划分区间对待定样本进行分类标记,训练集中概率超过0.7 的待定样本与上一轮的正样本合并确定为新的正样本,低于0.45 的待定样本确定为新的负样本,从而产生三分类训练集,包含正样本、负样本和处于[0.45,0.7]区间的待定样本。对该训练集采用随机森林作为三分类学习器进行数据集的多轮迭代更新,循环9 次后,停止产生新的正负样本,学习器训练完成。以该模型对测试集进行预测,得到结果如表4 所示。

表4 PU learning模型分类结果
根据预测结果可知,模型正样本查全率为12092/15683=80.59%,查准率为12092/(12092+3139)=79.39%,其他待定样本识别比例r=32305/138051=23.4%。说明模型在对能够识别绝大部分老年人,同时也将年轻人的误判比例控制在了一定程度。其他待定样本识别比例在23.4%左右。
3.3.3 AutoEncoder 模型分类能力分析
选择训练集中的正样本进入AutoEncoder 模型训练,模型设定参数包括完整训练次数、批数据量和学习率epoch=50,batch=1000,lr=0.001,得到模型损失函数曲线,如图2 所示。由图可知,loss 函数在10 个epoch 之内极速下降,随后趋于稳定,模型完成收敛。计算正样本的平均绝对误差mae,绘制正样本平均绝对误差mae 的分布图并确定正样本的mae 阈值为0.06,如图3 所示。
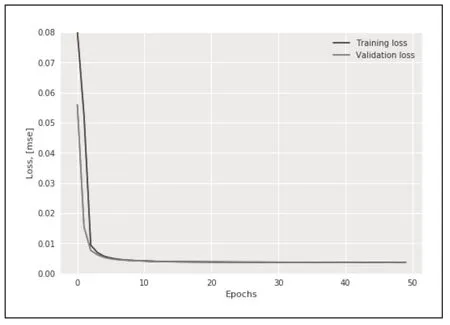
图2 损失函数曲线图

图3 mae 分布图
根据预测结果可知,模型查全率为12565/15683=80.12%,查准率为12565/(12565+4134)=75.24%,其他待定样本识别比例r=35348/138051=25.61%。说明模型对潜在老年人用户群体具有一定的识别能力,同时误判相对较少。其他待定样本识别比例在25.6%左右。

表5 AutoEncoder模型分类结果
3.3.4 识别结果输出
由于半监督算法是利用已有标签对未标记标签进行预测,易受样本质量、特征有效性等因素的影响,进而影响到模型整体的准确性和泛化能力。为降低上述因素影响、提高识别人群的可靠性、满足不同业务经营要求,对两种算法识别的正例概率区间[0.5,1]和mae 区间[0,0.06]进行等分,分别形成5 个概率区间并由低到高赋值1-5 分,两者相加产生0-10 分的分值区间,计算人群的综合得分。
根据实际业务需求和专家经验判断,本文确定综合得分较高(>=8 分)的老人人群作为业务营销的目标人群,输出老年人13543 人。由于正样本可根据实名制年龄准确提取,因此输出老年人数即为正样本总数15683 人。总计输出老年人人数29226 人,占总体人群19.01%。

表6 输出结果分析表
本文针对现有潜在老年人识别业务场景中有监督算法实用性不大的问题,提出一种基于中国移动数据,结合PU learning 算法和AutoEncoder 算法的老年人识别算法,通过对未有明确标记的数据样本进行分类器迭代标记以及输出误差阈值,并结合两种算法结果进行综合得分计算,根据得分识别老年人群,以此提升老年用户群的识别准确率。通过数据验证结果可以得出老年人用户群识别占比符合大数据统计结果。由此,基于中国移动数据与各行业数据的融合互补,提高银发市场用户识别准确率,向其推荐适配的适老化服务产品,能够更有利于社会养老结构优化,从而促进社会稳定与经济效益发展。
猜你喜欢区间标签样本你学会“区间测速”了吗中学生数理化·八年级物理人教版(2022年9期)2022-10-24用样本估计总体复习点拨中学生数理化·高一版(2021年2期)2021-03-19全球经济将继续处于低速增长区间中国外汇(2019年13期)2019-10-10无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30推动医改的“直销样本”知识经济·中国直销(2018年8期)2018-08-23不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09随机微分方程的样本Lyapunov二次型估计数学学习与研究(2017年3期)2017-03-09标签化伤害了谁公民与法治(2016年10期)2016-05-17村企共赢的样本中国老区建设(2016年1期)2016-02-28区间对象族的可镇定性分析北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27




