赵 威,宋建辉,刘砚菊,刘晓阳
(沈阳理工大学自动化与电气工程学院,沈阳 110159)
近年来,随着信息科技逐渐进步,基于人工智能的文字识别技术运用于诸多领域。
文本图像容易受拍摄设备和拍摄环境的影响,图像分辨率较低,传统的文字识别算法较难准确地识别出文本图像中的信息,为文字识别工作带来较大困难[1]。文本图像分辨率的高低直接影响文字识别的准确度,从低分辨率(Low Resolution,LR)图像中识别文本是重要的研究内容。
图像超分辨率重建算法主要包括超分辨卷积神经网络(SRCNN)算法[2]、加速的超分辨卷积神经网络(FSRCNN)算法[3]、基于拉普拉斯金字塔结构的图像超分辨率重建网络(LapSRN)算法[4]、基于生成对抗网络的超分辨率重建网络(SRGAN)算法[5]、文本超分辨网络(TSRN)算法[6]。SRCNN 算法首先利用双三次插值的方式把LR图像扩大到目标尺寸,然后经过超分辨率重建网络拟合数据集中的真值图像,最后输出超分辨率(Super Resolution,SR)图像。
该算法的网络结构简单,但应用于文本图像时效果有限。
FSRCNN算法是SRCNN 算法的改进,主要在网络中加入了反卷积层以扩大输入图像的尺寸,将LR 图像直接作为网络的输入,省去了网络之外扩大图像尺寸部分,训练时只需要微调反卷积层。
相较于SRCNN 算法,FSRCNN 算法在不降低重建效果的前提下训练速度有了很大提升,但其对图像特征的利用不够充分。
LapSRN 算法可以实现测试集的实时SR 图像生成,其骨干网络是SRCNN,在此基础上加入拉普拉斯金字塔结构,实现了一次运行过程中生成多张中间结果图像作为不同倍数的SR 图像,相比FSRCNN 算法,降低了计算的复杂性。
SRGAN 算法的最大特点是可以将LR 图像重建出拥有高感知质量和多细节,即人肉眼感知舒适的SR 图像,但SRGAN 算法在训练和测试过程中的稳定性有待提高。
TSRN 算法骨干以SRGAN 网络为基础构成,相比SRGAN 算法,该网络增加了一个中心对齐模块解决训练集和测试集中图片不对齐问题,对文本图像中不对齐的像素进行调整,还根据梯度轮廓先验[7]提出了梯度先验损失锐化文字边缘,但该算法在提取图像特征部分有待改进。
本文针对LR 文本图像中文字的特点,提出基于改进TSRN 的图像超分辨率重建算法。
在TSRN 的基础上引入信息蒸馏块(IDB)[8],在提取输入图像浅层特征后,通过叠加4 个IDB 加强特征图在细节处的有用信息,从而输出更为清楚的SR 图像,实现对LR 文本图像的准确识别。
本文算法可更充分地利用提取到的图像特征,提升图像的重建效果。
TSRN 算法把二进制掩模和彩色三通道(RGB)图像连接起来构成RGBM 四通道图像作为网络的输入。
针对数据集中高分辨率(High Resolution,HR)图像和LR 图像像素不对齐导致训练时产生双影和图像失真的问题,TSRN 首先采用空间转换网络作为对齐模块对文本图像进行预处理,并实现端到端学习,校正后图像中的伪影问题有所改善,图像中的文字水平规范,文字区域位于图像中央且对齐;
然后采用卷积神经网络提取文本图像中的浅层特征,将浅层特征输入到5重序列残差模块(Sequential Residual Block,SRB)中进行高级特征信息提取;
最后通过上采样模块和卷积神经网络生成SR 图像。
本文在TSRN 的基础上加入IDB 增强浅层特征信息,提出一种用于提高LR 文本图像清晰度的超分辨率重建算法。
改进的TSRN 框架如图1所示。
网络的输入是一张LR 文本图像,经过对齐模块实现图像的像素对齐,再经过浅层特征提取模块得到文本图像的浅层特征,并输入IDB 中进行特征增强。
本文通过叠加4 个IDB 处理后再经过5 个SRB 输出残差学习结果,最后经过上采样模块和卷积神经网络生成SR 图像。

图1 改进的TSRN 框架图
TSRN算法通过卷积神经网络进行文本图像浅层特征的提取,会导致后面模块表达能力受限。因此,本文叠加4 个IDB 增强文本图像浅层特征。
IDB 中包括增强单元和压缩单元两个部分[8]。
增强单元加强文本图像的浅层特征,增加特征通道数量,使提取的浅层特征拥有更多有效的信息,如文本图像的笔画细节等,增强单元网络如图2 所示。
图中F是增强单元的输入,表示提取的浅层特征;
P表示图像通道之间的分割操作;
S表示图像通道之间的拼接操作。
增强单元为2个卷积神经网络,每个卷积神经网络包括3 个卷积层,每个卷积层后面连接一个激活层。F经过第一个卷积神经网络后输出短路径特征,并经由P分为两部分,分别是增强短路径特征F1 和保留短路径特征F2。F1 输入到第二个卷积神经网络得到长路径特征F3,F2 和F经过图像通道拼接操作输出局部短路径特征F4,将长路径特征与局部短路径特征合成,得到增强单元的输出F5,其表达式为
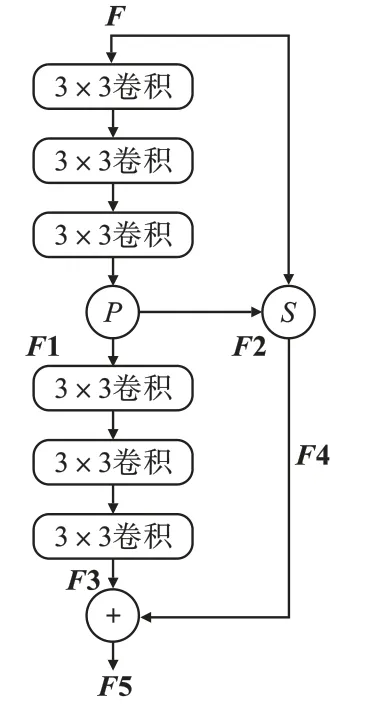
图2 增强单元网络
式中A表示网络的卷积和激活过程。
超分辨率重建算法的损失函数采用均方误差,其计算式为[9]
式中:L1为均方误差;
IHR为数据集中HR 文本图像;
ISR为经过超分辨率重建算法得到的SR 文本图像;
n为数据集中HR 文本图像的数量。
文本图像中文字色彩一般和背景有明显差异,故采用图像梯度损失函数,以加强文字的轮廓和线条,使输出图像中的文字更加清楚,图像梯度损失函数LGP计算式为
式中:x为图像中文字线条对应的像素;
Ex表示最小化操作,目的是使SR 图像更加清晰;
∇IHR(x)表示数据集中HR 文本图像的梯度场;
∇ISR(x)表示经过超分辨率重建算法得到SR 文本图像的梯度场。
总损失函数L的表达式为
式中λ1和λ2分别为L1和LGP的自适应权重系数,本文设置为λ1=1、λ2=10-4。
本研究使用TextZoom 数据集。
TextZoom 数据集常用于LR 文本图像的超分辨率重建,该数据集由数码相机拍摄的图像组成,相机在不同焦距下拍摄出不同分辨率的文本图像,在短焦距下拍摄的图像可作为LR 图像,在较长焦距下拍摄的图像作为HR 图像[10]。
数据集包含约三万张成对的LR 图像和HR 图像,选取70%作为本文的训练集,30%作为测试集。
本文中HR 图像作为训练模型的真值。
当拍摄的图像高度相同时,焦距越小的图像越模糊,文字识别的难度也就越大。
将数据集按照识别难度分为三个子集:容易子集、中等子集和困难子集,本研究的主要目的是提高各子集中文本图像的文字识别准确率。
数据集中各子集的部分图像示例如图3 所示。

图3 数据集中各子集部分图像示例
TextZoom 数据集中图像像素偏移和部分图像较模糊,存在LR 图像和HR 图像的像素不对齐现象,任何轻微的相机镜头移动都可能导致数十个像素的偏移,尤其是短焦距拍摄。
从图3 可以看出,像素不对齐的变化无特定规律,随着数据集子集难度的增加,图像像素的偏移程度和图像模糊程度也更加严重。
使用容易、中等和困难三个子集分别对本文的超分辨率重建算法进行训练和测试,训练集的图像为两两对应的HR 图像和LR 图像,在训练过程中,LR 图像作为改进网络的输入,通过超分辨率重建生成SR 图像。
为全面评估本文算法的重建效果,将本文算法与原始 TSRN 算法、SRCNN 算法、FSRCNN 算法、LapSRN 算法进行比较,上述算法均使用TextZoom 数据集进行训练和测试。
几种超分辨率重建算法输出的SR 文本图像如表1 所示。

表1 几种算法输出的SR 图像
由表1 可以看出,相比其他算法,本文算法输出SR 图像中的文字线条更加清晰,文字与图像背景的对比更加明显。
本文算法能从模糊的LR 文本图像中重建出更加清晰的SR 文本图像,提高了LR 文本图像的分辨率。
本文算法与TSRN 算法恢复的文本图像细节如表2 所示。

表2 本文算法与TSRN 算法恢复的文本图像细节
由表2 可以看出,通过本文算法重建后,左边图像可以比较清晰地看出字母a 的线条,右边图像中文字线条和图像背景的对比也更加明显。
相较于TSRN 算法,本文算法对文字细节处理更好,证明了本文算法的有效性。
不同的超分辨率重建算法对不同子集输出图像的峰值信噪比( PSNR) 和结构相似性(SSIM)[11]结果如表3 所示。
PSNR 为评定图像质量的指标,其值越大,表示图像质量越好。
由于使用对齐模块导致轻微的像素偏移,故本文算法在中等子集得到的PSNR值相比SRCNN 算法稍低,在困难子集得到的PSNR 值比LapSRN 算法稍低。
因容易子集的图像较清晰,图像像素的偏移程度不高,故对齐模块对容易子集的影响不大,本文算法在容易子集的PSNR 值较高。
SSIM 为评定两张图像一致程度的指标,SSIM 的值越接近1,代表两张图像的相似性越高。
本文评定数据集中的HR 图像和重建算法输出的SR 图像的一致程度,由表3 可以看出,相比于其他算法,本文算法在各子集的SSIM 值均最高。
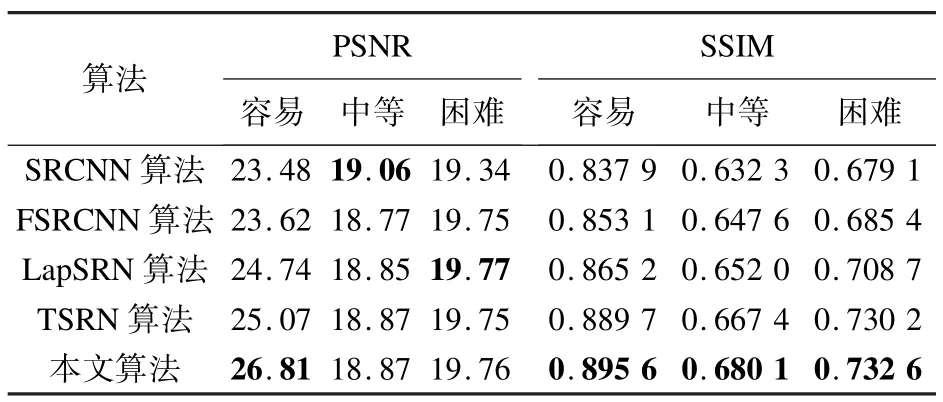
表3 不同算法的PSNR 和SSIM 结果
本文使用卷积循环神经网络(CRNN)模型分别对TextZoom 数据集中容易、中等、困难三个子集的LR 图像和HR 图像进行文字识别,分析文字识别准确率。
数据集中图像的内容均为字符串,文字识别的结果可能出现一个字符串中部分字符识别正确、部分字符识别错误的现象,文字识别准确率以识别正确的字符数占已识别字符数的比表示。
平均文字识别准确率为数据集中容易、中等、困难三个子集文字识别准确率的平均值。
针对TextZoom 数据集中图像的文字识别准确率如表4所示。

表4 TextZoom 数据集中图像的文字识别准确率 %
由表4 可知,数据集中LR 图像的平均文字识别准确率仅为25.1%,HR 图像的平均文字识别准确率为61.2%,可见文本图像分辨率对文字识别准确率影响很大。
为进一步证明本文算法的有效性,使用卷积循环神经网络对不同超分辨率重建算法生成的SR 图像进行文字识别,由于数据集中LR 图像被分为三个子集,故生成的SR 图像也分为三个子集。
文字识别准确率的比较结果如表5 所示。
由表5 可以看出,本文算法生成SR 图像的平均文字识别准确率达到41.9%,相较于LR图像的平均文字识别准确率提高了16.8%,提高效果显著。
相较于原TSRN 算法,本文算法生成SR 图像的平均文字识别准确率提升了1.2%;
相较于SRCNN 算法、FSRCNN 算法和 LapSRN 算法,本文算法生成SR 图像的平均文字识别准确率分别提升了14.9%、11.2%和9.4%。
说明本文算法的重建效果更好。

表5 不同算法生成SR 图像的文字识别准确率比较 %
为提高LR 文本图像的分辨率,本文对TRSN的网络结构进行了改进,加入4 个叠加的IDB 提高图像的分辨率。
通过TextZoom 数据集对本文算法进行训练和测试,结果表明,改进的重建算法可将LR 图像转化为更清晰的SR 图像,图像中文字的线条更加分明、文字细节更加清楚。
使用CRNN 模型对LR 图像和重建后的SR 图像进行文字识别并计算文字识别准确率,结果表明,改进的重建算法生成SR 图像的平均文字识别准确率达到41.9%,较LR 图像的平均文字识别准确率显著提高,相较于原TSRN 算法,平均文字识别准确率提升了1.2%。
本文提出的算法有效,重建效果更好。
猜你喜欢子集分辨率卷积拓扑空间中紧致子集的性质研究安庆师范大学学报(自然科学版)(2021年1期)2021-11-28基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02连通子集性质的推广与等价刻画阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13关于奇数阶二元子集的分离序列南京大学学报(数学半年刊)(2020年1期)2020-03-19EM算法的参数分辨率数学物理学报(2019年3期)2019-07-23从滤波器理解卷积电子制作(2019年11期)2019-07-04原生VS最大那些混淆视听的“分辨率”概念家庭影院技术(2018年9期)2018-11-02基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20基于深度特征学习的图像超分辨率重建自动化学报(2017年5期)2017-05-14一种改进的基于边缘加强超分辨率算法成都信息工程大学学报(2017年6期)2017-03-16




